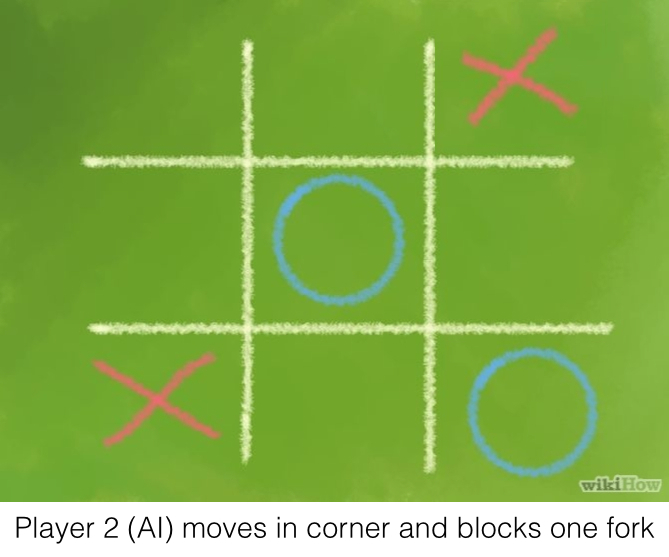
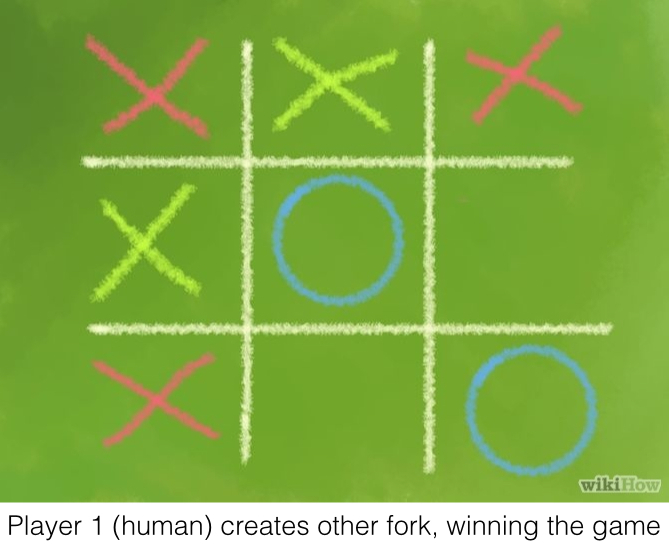
You may recall that just a couple of days ago I posted a solution on how to solve Tic-Tac-Toe. As it turns out, I greatly overcomplicated the problem. Or, well, kind of. I actually just solved Tic-Tac-Toe for humans. I wrote an algorithm on how humans might go about solving the problem. However, the great thing about computers is that they are not humans. They can do a lot of computations and remember a lot of stuff. There’s an algorithm to solve this problem, and it’s called Minimax.
Minimax
As my Google searches evolved from “tic tac toe strategy” (which had lead me to solving the problem for humans) to “tic tac toe algorithm”, I noticed people talking about this thing called “minimax” on programming forums. I think it’s actually the de facto way to solve Tic-Tac-Toe, as there are hundreds resources which detail how to apply Minimax to Tic-Tac-Toe. Well, oops. I like solving things and I don’t like doing something just because the Internet tells me it’s the right thing to do. In order for me to use it, I had to understand how it works.
Minimax is a decision rule which minimizes the maximum possible loss. It involves one maximizing player (in this case, the AI), and one minimizing player (the human opponent). It was developed for zero-sum game theory, which is the mathematical representation of a situation in which a player’s gain or loss is exactly balanced by the loss or gain of the opponent player. If the total gains of all players are added and total losses of all players are subtracted, the result will be zero, thus zero-sum. There’s also a Minimax theorem, first published by John von Neumann (of von Neumann architecture, which almost all modern computers use) in 1928:
The minimax theorem states:
For every two-person, zero-sum game with finitely many strategies, there exists a value V and a mixed strategy for each player, such that
(a) Given player 2’s strategy, the best payoff possible for player 1 is V, and
(b) Given player 1’s strategy, the best payoff possible for player 2 is −V.
Therefore, the AI needs to pick the move with the best possible payoff. What do all of the moves look like? How do we calculate the payoff?
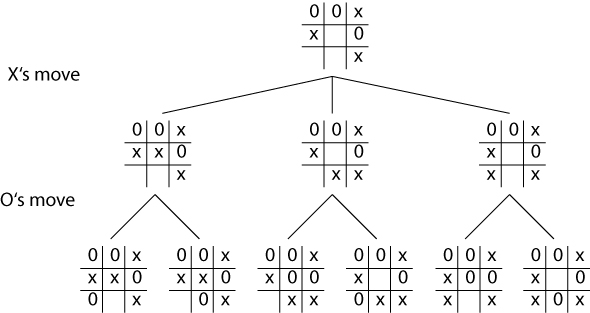
The Set of Moves Forms a Tree
In Minimax, each possible move is evaluated, given a score, and then compared to the other possible moves. The one with the best payoff is chosen. We have a set of possible moves, which is like a set of paths, and ends up looking something like this:
Minimax looks ahead at all possible paths, by scoring the state of the board at its maximum depth, recursively scoring the board in the parent node by choosing the best child, until the score and position reaches the root.
Let’s look at the pseudocode:
12345678910111213141516171819202122232425262728
defminimax(depth,player)ifgameover||depth==0returncalculated_scoreendchildren=alllegalmovesforplayerifplayerisAI(maximizingplayer)best_score=-infinityforeachchildscore=minimax(depth-1,opponent)if(score>best_score)best_score=scoreendreturnbest_scoreendelse#player is minimizing playerbest_score=+infinityforeachchildscore=minimax(depth-1,player)if(score<best_score)best_score=scoreendreturnbest_scoreendendend#then you would call it likeminimax(2,computer)
One important thing to note is the depth. You don’t necessarily need to look ahead at all possible paths, just a few moves ahead. Also notice that this algorithm is recursive and depth-first.
Calculating A Score
How do we actually give a score to the state of of the board? This is the only part of the algorithm that ends up being heuristic. You have to choose a heuristic board evaluation function to calculate this value. I chose to calculate a score for each line (the three rows, the three columns, and two diagonals) on the board, and then sum these values. I scored each line as follows:
+100 for each three-in-a-row for the AI
+10 for each two-in-a-row (and empty cell) for the AI
+1 for each one-in-a-row (and two empty cells) for the AI
-1 for each one-in-a-row (and two empty cells) for the other player
-10 for each two-in-a-row (and empty cell) for the other player
-100 for each three-in-a-row for the other player
0 for all other states
It’s nice how simple it ends up being to score a board state.
Minimax, But Better
There’s a different algorithm that makes Minimax better, called Alpha-beta pruning. This eliminates paths that are worse than paths that have already been evaluated. Therefore, you have to store a few more values: alpha, which holds the maxmimum score for the maximum path, and beta, which holds the minimum score for the minimum path. You throw away a path when its alpha value is >= the beta value. The algorithm is extremely similar, and the pseudo code is as follows:
defminimax(depth,player,alpha,beta)ifgameover||depth==0returncalculated_scoreendchildren=alllegalmovesforplayerifplayerisAI(maximizingplayer)foreachchildscore=minimax(depth-1,opponent,alpha,beta)if(score>alpha)alpha=scoreendifalpha>=betabreakendreturnalphaendelse#player is minimizing playerbest_score=+infinityforeachchildscore=minimax(depth-1,player,alpha,beta)if(score<beta)beta=scoreendifalpha>=betabreakendreturnbetaendendend#then you would call it likeminimax(2,computer,-inf,+inf)
In alpha-beta pruning, the alpha and beta values are passed along with each recursive call of minimax. The path is discarded (by calling break within the loop) if at any moment in the path, alpha is greater than or equal to beta.
The score depends on which player minimax is currently being called on: if it’s the maximizing player (the AI), alpha is returned as the score, and beta if it is the minimizing player.
Check Out My Code
If you would like to see how I implemented alpha-beta pruning for a Tic-Tac-Toe AI, check out my Github repository. The other solution is now on a branch called heuristic-solution.
Also, it’s remarkable how much simpler this solution is versus the heuristic solution. Game theory and decision theory are really cool, and are definitely something I should read about more.
A few months ago, when I had decided that I wanted to quit my job as a C++ developer and become a web developer, I applied to the Flatiron School to immerse myself in web technologies. During the application process, I was assigned a code challenge, to create a game of Tic-Tac-Toe, played either by two humans or a human against an AI player, in the language of my choosing. To challenge myself, I chose Ruby, a language I had never used before but figured that there was never a better moment to start. I applied all of the object-oriented programming fundamentals I knew from my time coding in C++ and Java, and ended up with somethiing I was pretty proud of.
Refactoring
After the class was over, only four months after I wrote my first Ruby code, I went back to build upon what I had previously done. It’s fun to see how much better you’ve gotten at something, in my opinion. It was funny to see all of the non-Rubylike things I had done:
Accessing data elements outside of a class’s initialize method. For example, inside of my Board class:
123
defset(index,mark)@board[index]=markend
This I changed to
123
defset(index,mark)self.board[index]=markend
Using explicit return statements at the end of methods. I was used to the world of C++ in which best practice is to be as explicit as possible, otherwise your code is really difficult to read. Again, from the Board class:
123
defget(index)return@board[index]end
I changed this method to
123
defget(index)self.board[index]end
Unconventional method naming. What was with the question marks and exclamation points? I had written stuff like this (from Board class again):
Also, what’s with those if and else statements? I was used to the C++ world in which that kind of logic ends up so verbose. I fixed it to look like this:
Much more compact and readable, and better error checking!
Designing an AI
Once I had fixed my code to fit with Ruby conventions, I had a larger task to accomplish: make the AI unbeatable. I felt confident, as I had written an AI before for Battleship. However, it turns out that designing a Battleship strategy is different from Tic-Tac-Toe. A lot different, in fact, and it tripped me up.
When I designed the AI for Battleship, I created a board of probabilites, based on the likelihood of a ship being in a certain position on the board. I tried to do the same for Tic-Tac-Toe, even creating a ProbabilitiesBoard class that was initialized to look like this
123456789
||3|2|3___|___|___||3|4|2___|___|___||3|2|3||
in which each number represents the number of different ways a player can win, based on the number of rows that interesect a position. Unfortunately, as I played out a few games and tried to recalculate my probabilities, I realised my calculation wasn’t robust enough. It didn’t take into account enough different possibilites of gameplay. Because, in Tic-Tac-Toe, unlike Battleship, you also have to block another player.
Tic-Tac-Toe is not like Battleship
So I was back to square one. I started to think about the game in certain types of moves. Certain moves won the game by making three in a row, certain moves blocked another player, certain moves created a dual threat, and so on. I had distilled the types of moves into a hierarchy as well, which looked something like this:
If you have two in a row, add a third to the row to win the game.
If your opponent has two in a row, add a third to the row to block him or her from winning.
Place your mark on the board strategically, bringing you closer to winning.
This was something. I quickly implemented two methods in the ComputerPlayer class, find_winning_move and find_blocking_move. Because I found that I need to iterate over all of the different rows in the board, I decided to store them in my Board class:
As you see, I created a separate method in the ComputerPlayer class called find_two_in_a_row, which iterates though all of the rows and tries to find two in a row of a mark passed in as a parameter. As soon as it finds a row, it returns with the empty position in the row.
A Hierarchical Strategy
I had created two crucial methods whith made the AI a lot smarter, but I was lost on the rest of the strategy. I decided to ask the Internet for some inspiration, and I found some help on Wikihow and Quora. However, I found it difficult to find patterns. I didn’t want to add a lot of if and else statements which check for things like “if the AI player went first and then the opponent moved in a corner” then “the AI player should put a mark in the opposite corner”. It didn’t feel right, and I felt like I could do better.
I had an aha moment when I came across this answer to a StackExchange question. It states that a Tic-Tac-Toe strategy is based on a hierarchy of types of moves. Of course! I had gotten halfway there when I realized that winning was more important than blocking which was more important that other types of moves, but I hadn’t been able to pin down the other types of moves. The hierarchy of moves is
The following algorithm will allow you (or the AI) to always deny your opponent victory:
Win:
If you have two in a row, you can place a third to get three in a row.
Block:
If the opponent has two in a row, you must play the third to block the opponent.
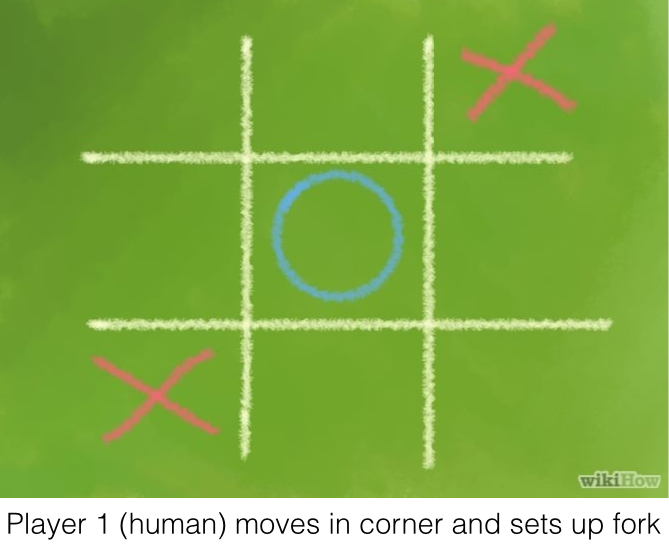
Fork:
Create an opportunity where you have two threats to win (two non-blocked lines of 2).
Blocking an opponent’s fork:
If there is a configuration where the opponent can fork, you must block that fork.
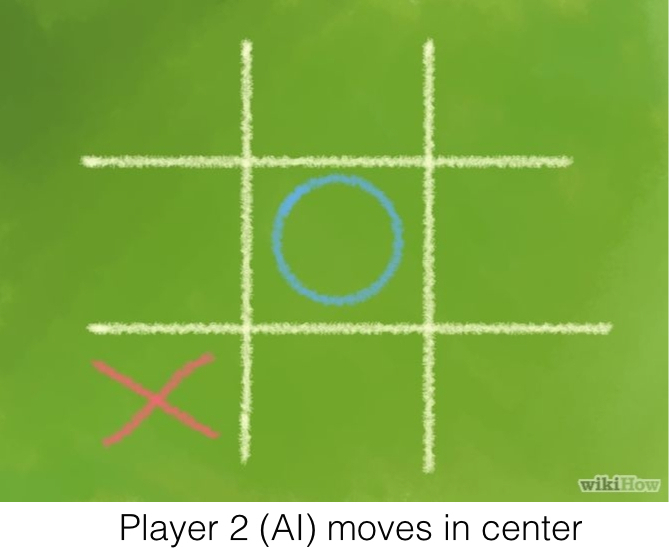
Center:
You play the center if open.
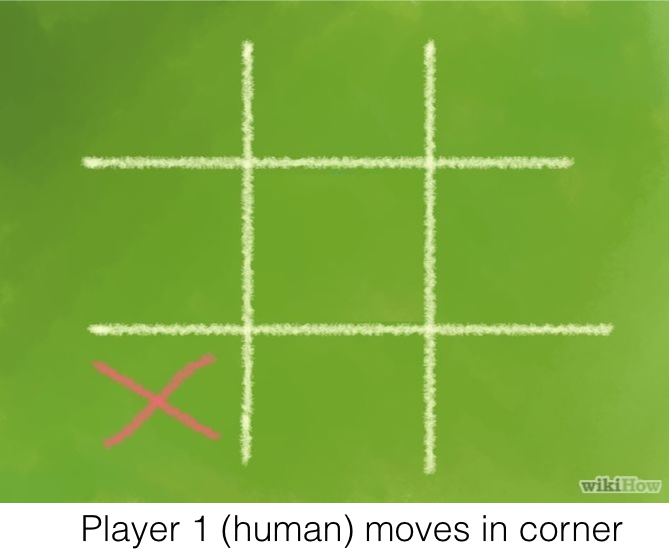
Opposite corner:
If the opponent is in the corner, you play the opposite corner.
Empty corner:
You play in a corner square.
Empty side:
You play in a middle square on any of the 4 sides.
Pick the highest possible on the list
I was able to knock out most of these methods pretty quickly, except for finding forks and blocking an opponent’s forks. These turned out to be trickier than I expected.
Finding Forks
In the case of finding a fork, I realized that a player only needed to find one in order to create a dual threat (and therefore win the game). I managed to map out an algorithm:
Iterate through all rows on the board
if a row contained only one of the player’s mark, and nothing else,
then iterate thorough all overlapping rows
if an overlapping row contained only one of the player’s mark, and nothing else
if it’s not the position in which the two rows overlap,
then you’ve found a fork
return the position in which the two rows overlap
I already knew how to iterate though all of the rows, but how do you find all of the overlapping rows? It turns out this is easier than I expected. I wrote a method for the Board class called overlapping_rows which takes a row as a parameter.
All this method does is select the rows that contain a position that is also in the row passed in, just as long as it is not the same row. The actual code in the ComputerPlayer class ended up looking like this:
The method returns the position to create a fork as soon as it finds the first fork.
Blocking All Forks, Not Just One
At first, I thought that after I had implemented a method that created forks, I could use the same code to block forks. I figured out there was a problem when I was testing with the following game:
In the process of blocking one fork, the AI had left another one open. Therefore, it wasn’t just as simple as finding the first fork. The AI had to find them all, and then choose the optimal place to block. First, finding all forks:
The only problem with this method is that as it iterates over all rows, it inserts duplicate forks in a different order. Thus, the last line of the method removes these duplicates.
Then, I had to figure out a way to pick the proper blocking spot. I tried things like finding the position that occurs the most in the rows, but it turns out there was no correlation. I finally realized that the way to find the proper blocking move is to look ahead, by checking all moves that would block a fork. I did this in a method called select_blocking_fork_move, which takes a list of possible forks as a parameter. The line
and then, the AI checks for one of two scenarios. First, it checks that if the blocking move creates two in a row, and then the opponent moves to block, it doesn’t create another fork for the opponent. That’s a lot, but I think it makes more sense if you look at the code:
As you see, I wrote a method called contains_fork? which checks the board for forks. The else statement within the loop checks if the possible move does, in fact, block all possible forks:
The body of the else statement first removes the test opponent mark that had been put on the board, and then checks if there are any possible forks. If there aren’t, even though this move doesn’t create two in a row, it blocks the opponent from creating a fork.
Of course, there are some things that I’m not happy about in terms of how my code turned out.
Breaking from loops using return statements
For this project, I am a big offender of breaking out of loops using a return statement. For example, from my ComputerPlayer class:
It’s not very Ruby-like, I know. Because of my C++ and Java background, in which it’s totally kosher to do that, it is one of my first instincts. I did try to refactor and figure out another way, but I think the way I have it now is the most clear, at least to me.
Command-line interface
I find it to be a little annoying to use. I guess I could refactor it to be a web application, but that’s a lot more work, and the point of this was to create an unbeatable AI.
Storing rows in Board class
The “row” is the only part of this application that’s not object-oriented, which I’m not happy about. In my case, a row is an array of length three that holds three positions on the board. I hardcoded these values and stored them as part of the board. I also dislike how the method overlapping_rows takes a row as an argument, which is just an array. It’s just not right.
In the future, I would figure out how to make a row an object and not just data.
Check Out My Code
Now you know how to solve Tic-Tac-Toe! Yay!
If you want to try to find possible flaws in my logic, or look more at my implementation of Tic-Tac-Toe, please check out the heuristic-solution branch on my Github repository. Or, if you know of a better way to solve this, let me know.
My last post was a delirious declaration that I had finally made something with Web Audio. Here it is, a drum sequencer in the browser. Now I want to explain how I did it. First, what is Web Audio, and why do we need it?
The Web Audio API is a versatile system for controlling audio in the web. It does this inside an audio context, which you declare as follows:
1
varcontext=newAudioContext();
You then create sources, either by loading a song or sample via an AJAX request (though you can’t use jQuery since it doesn’t support responses of type ‘arrayBuffer’:
123456789101112131415161718
varsongBuffer=null;//for multiple browser supportwindow.AudioContext=window.AudioContext||window.webkitAudioContext;varcontext=newAudioContext();functionloadSong(url){// the url can be full path or relativevarrequest=newXMLHttpRequest();request.open('GET',url,true);request.responseType='arraybuffer';// Decode asynchronouslyrequest.onload=function(){context.decodeAudioData(request.response,function(buffer){songBuffer=buffer;},onError);}request.send();}
Once you have sources, you route sounds through a series of audio nodes to add effects, such as reverb, filtering, and compression. It is also modular, meaning it is simple to change the routes to add or remove effects. It is analogous to physical synthesizers and modular synthesizers. The last node in the audio routing graph is the destination node, which is responsible for actually playing the sounds. Here’s a routing example:
1234567
functionplaySound(buffer){// creates a sound source from buffer just loadedvarsource=context.createBufferSource();source.buffer=buffer;// tell the source which sound to playsource.connect(context.destination);// connect source to context's destination (the speakers)source.start(0);// play the source now}
Cool, so now we can play audio. As soon as I figured out how to do this, the first thing I wanted to learn how to do is how to sequence audio events, because that’s how you make music: you organize sounds in time. This is a deep, deep rabbit hole. On the introduction to Web Audio tutorial, they have an example which synchronizes to the Javascript clock. But this is bad. Very bad. The Javascript clock is not precise, and therefore if you synchronize audio events to it, there will be noticeable latency and stuttering. You must synchronize to the Web Audio clock, which is a signal from an actual hardware crystal on your computer (and therefore very precise).
Another problem is scheduling. Web Audio has no built in scheduler. Therefore, you have to build your own (or use a library that has one, for example, WAAClock or SoundJS). You also have to think how far ahead you want to schedule your audio events. For example, if you have the code (which is synchronized to the Javascript clock)
12345678
for(varbar=0;bar<2;bar++){vartime=startTime+bar*8*eighthNoteTime;// Play the hi-hat every eighth note.for(vari=0;i<8;++i){playSound(hihat,time+i*eighthNoteTime);}}
and you want to change tempo, what do you do? You can’t unschedule the notes once you’ve told them to play. You would have to add a gain node to control the volume, turn off the volume on the now off-tempo loop, and then create a new loop with the new correct tempo. And ad infinitum every time you want to change the tempo again.
That’s awful, and there is a better way. After reading A Tale of Two Clocks a few times until it finally made sense. The way to make a good scheduler is to schedule one note ahead of time, and to synchronize it to the Web Audio clock. Unfortunately, it’s easier said than done. Your scheduler function ends up looking something like this:
But scheduleAheadTime and nextNoteTime have to be tweaked according to your use case. In my case, I ended up using the same parameters as used in the Google Shiny Drum Machine and it seems to be okay. Let’s look at my code for the core scheduling functionality:
functionhandlePlay(event){noteTime=0.0;startTime=context.currentTime+0.005;rhythmIndex=0;schedule();}functionhandleStop(event){clearTimeout(timeoutId);}functionschedule(){varcurrentTime=context.currentTime;// The sequence starts at startTime, so normalize currentTime so that it's 0 at the start of the sequence.currentTime-=startTime;while(noteTime<currentTime+0.200){varcontextPlayTime=noteTime+startTime;//Insert playing notes here//Insert draw stuff hereadvanceNote();}timeoutId=setTimeout("schedule()",0);}functionadvanceNote(){// Setting tempo to 60 BPM just for nowvartempo=60.0;varsecondsPerBeat=60.0/tempo;rhythmIndex++;if(rhythmIndex==LOOP_LENGTH){rhythmIndex=0;}//0.25 because each square is a 16th notenoteTime+=0.25*secondsPerBeat;}
Okay, there’s a lot going on here, so let’s break this down. Note that I didn’t include anything about playing notes or updating the visuals as I just wanted to focus on the timing/scheduling.
First, in handlePlay(), we reset noteTime, which represents the length of a note. And then we set startTime, which includes an offset to take into account stuff happening in the main Javascript execution time (e.g. garbage collection).
Then, in schedule, we first check if we need to sequence audio events, depending on noteTime and currentTime. Note that the 200 ms offset here represents the variable scheduleAheadTime in the previous example. The while loop inside of the function schedule() is run again and again until we’ve scheduled all notes that fall within our lookahead interval. Therefore, as we schedule more notes, and increment noteTime based on the tempo of the song (in advanceNote()):
Since we’re assuming a 4/4 time signature, to obtain noteTime we multipy secondsPerBeat by 0.25 since each note is a 16th note. Once we’ve scheduled all of the notes that fall within our lookahead interval, the condition of the while loop in schedule()
1
while(noteTime<currentTime+0.200){
will fail. Lastly, what’s with the last line of schedule()?
1
timeoutId=setTimeout("schedule()",0);
setTimeout is a Javascript library function that executes a function after a certain period of time. Therefore, this tells Javascript to call the schedule() function after 0 ms. So basically, call schedule() again right after it’s scheduled all notes within out lookahead interval and begin the process over again.
Lastly, there’s the rhythmIndex variable in advanceNote():
This variable simply represents where you are in the context of the loop, and resets when the sequence reaches then end so that it loops.
Cool, so now we can sequence audio properly! Well, kind of. As is pointed out in this StackOverflow, synchronizing to the Web Audio clock does not mean that your audio is synchronized to the animation frame refresh rate. However, it’s simple to fix this. You can replace
1
timeoutId=setTimeout("schedule()",0);
with
1
requestId=requestAnimationFrame(schedule());
and
1
clearTimeout(timeoutId);
with
1
cancelAnimationFrame(requestId);
requestAnimationFrame is awesome because the browser choses the frame rate based on the other tasks it is handling, and therefore the rate is more consistent, and if the current tab loses focus, requestAnimationFrame will stop running.
If you’ve got this scheduling thing down, and want to learn how to integrate it into our own application, I recommend checking out my code at Github to see how I did it.
Thanks for reading, and look out for a part two of this blog post, which will explain more in depth about audio routing graphs, and different types of nodes, i.e. how to add different types of effects.
In my college career, I majored in electrical engineering, and because of this, I learned about signal processing and audio. Now that I’m learning web development, I’ve been eager to combine my skills and delve into Web Audio, an API that allows you to do audio processing magic in the browser. This API allows you to create websites like Soundcloud or even remix songs algorithmically. I decided to create a basic drum machine, and then modify it to create a digital sequencer.
I first followed this Virtual Synth tutorial, which was a great place to start, but there were a few things I didn’t like about it:
No ability to create a sequence. What good is a drum machine without a sequencer (unless you’re Araabmuzik)?
Either I implemented the filter wrong, which is very possible, or it doesn’t work correctly. It doesn’t use a logarithmic scale, however, which is definitely a big mistake.
I threw a bunch of stuff together just to get a working app, but I think that my next step is definitely to pause for a moment and refactor.
I will write a tutorial in the future for this, but for now, since my brains hurts a lot, you can check out the current version of my Web Audio Sequencer. And, of course, check out my Github if you want to look at the code (latest commit as writing this post).
This past weekend I went to a hackathon, called Stupid Hackathon. It’s not the first hackathon I have ever been to, but it’s the first hackathon I’ve been to since learning web development. I was excited about it from the moment I first heard about it since the theme was “stupid shit nobody wants and dumb ideas.” There is so much I love about that. All in all, it was a great day, but for me, it was a massive failure. And that’s totally okay.
Learning to accept failure is hard. I think the only way to get better at it is to fail a lot. However, you can fail gracefully, and you can fail hard. You can other get depressed over it, or you can take it as a learning experience. I tried to do the latter, and so, here’s what I learned:
I completely overestimated my abilities. I thought I understood everything about Rails. Okay, maybe that’s not true, but I thought I could at least get a simple app up and running. The problem was that my app was not actually simple. The data models were different from anything I had ever worked with before, and I strugged to map out all of the model, view, and controller relationships. I also got way too caught up in trying to follow Rails conventions rather than just making something and fixing it later. It’s a hackathon, after all, and a stupid one at that.
I underestimated how much time each separate piece would take. There were a few moving parts, including integrating with Stripe and Amazon’s Mechanical Turk API. While using each one of these separate isn’t so hard, getting the whole thing to work together is. And all of these things add up.
I underestimated time, in general. I forgot that hackathons are full of interesting people who are very distracting because I want to talk to them. I learned the best approach is to make something relatively simple, a minimum viable product, and then go from there.
I’m pretty good at debugging. Once I had gotten exceedingly frustrated with my project, I went to help out a friend with a project. She was having some issues with her Chrome Extension, and I was able to throw in a few debugger statements in the right place and figure out what was going on. I also fixed the bug! It was cool, knowing that I’m good at breaking down a problem like that. I guess it makes sense though, since that’s mostly what I did at my previous job.
I got way too excited about my project before thinking about the other people around me. I should have focused on the skillset of the people around me rather than getting excited about my dumb idea. Working with people is kind of the point of a hackathon.
I need to get better at being impulsive. I spend too much time marinating on thoughts and not just doing sometimes. It’s like Drake says, YOLO.
Presentation is an important aspect of your hackathon project. It might be worth it to run across the street and buy matching bugundy turtlenecks with your project partner. It’s definitely worth it to make a great powerpoint, with lots of gifs and jokes.
The best part is that I got to be around a bunch of other awesome people making awesome things. There was a Chrome Extension that mimicked browsing the web from within the North Korean intranet. There was one that told you whether or not you were holding your phone. There was one that translated movie subtitles to emojis. Every single one was simultaneously stupid and brilliant. These are my favorite types of projects.
Oh, and I got a pretty cool free t-shirt of George Bush with a selfie stick.
I’m still in love with my project, despite having some rough moments with it, so maybe I’ll finish it one day. Hopefully. And at the next hackathon I go to, I’m going to kill it.
When I first learned git, I thought I understood it all. I had a grasp of the process of cloning a repository, making your own changes, and then making a pull request. I had made sense of it by making analogies to the old days when I worked in subversion. But then, I started to think about how to use git in production. And the question dawned on me: how do I synchronize with the master branch of the repository that I forked from? I understood the workflow of having a lot of local repositories and one remote, but when in came to multiple remote repositories, I was lost.
As it turns out, it’s easy to set up. First, make sure you’ve forked a repository, and have cloned your version locally.
The benefit of setting this up is that you can easily merge in the latest changes from the master of the project, but also have your own version. You can also not worry about accidentally pushing to the master of the repository you forked from.
The benefit of this for me, currently, is that I’m a student at The Flatiron School. Our lecture notes are a repository. By doing this, I can take better notes in lecture. I like to try to keep up, and type everything that’s happening in lecture. If I find that I have a typo or some other issue, I’ll forget about it and keep writing stuff along with the instructor. Then, when lecture is over, I’ll merge in what was happening in lecture, fixing everything that wasn’t working during lecture. I find that by doing this, I’m more engaged in lecture and the information sticks.
As a side note, watch out for duplicate migrations. If you’re following everything in class, you probably would have created the same migrations as the instructor but at a slightly different time. Just delete one of the duplicates and then commit your changes.
Coming from a background in compiled languages, the idea of metaprogramming is fascinating to me. In the world of C, writing and running programs are distinct actions. At runtime, a program cannot be altered. However, in Ruby, the actual code can be modified while it is executing. To those who only know Ruby or similar interpreted languages, it may not seem like a big deal, but to me, it’s the coolest thing ever. At a hackathon I went to once a guy wrote a self-modifying program in Python, and I thought it was black magic. I didn’t realize it was just a gift that comes with the language, and you didn’t have to do any serious hacking to dynamically alter the code.
Let’s just look at eval. Maybe this isn’t so exciting:
1
eval("2 + 2")# => 4
But then, consider this ditty:
123456789
puts"Please enter a phrase: "# pretend you entered Hello World herephrase=gets.stripputs"Enter the name of a string method: "# pretend that you entered upcase heremethod_name=gets.stripexp="'#{phrase}'.#{method_name}"putseval(exp)# => HELLO WORLDputs"#{exp}"# => 'Hello World'.upcase
That’s pretty cool. You just wrote a little program on the fly. What else can you do? You can write a program that writes programs.
program=""input=""line=""whileline.strip()!="q"print("?> ")line=gets.stripcaselinewhen''puts"Evaluating..."evalinputprogram+=inputinput=""when'l'puts"Listing the program you've written so far..."putsprogramelseinput+=lineendend
If you run this, you kind of have a REPL, but it’s significantly dumber than IRB:
Cool. So what other applications does metaprogramming have in Ruby besides writing REPL’s? As it turns out, it’s one of my favorite things I’ve learned about in Ruby thus far: ActiveRecord. When you define associations between models, whether it be belongs_to or has_many or anything else, the methods that you get for free are all generated on the fly. It does this using eigen or singleton classes. This is having the ability to define methods for specific instances of a class, after the class has already been defined. For example, say you define a class like so:
123456789101112
classRoomba# Some other methodsdefvacuum_floorwhilefloor.dirty?#vacuum for 5 secondsvacuum(5000)ifcloggedraiseRoomba::CloggedExceptionendendendend
Then you would instantiate it as
1
fido=Roomba.new
But say you got the newer model, which knows how to unclog itself. Then you could do something like
1234567
deffido.vacuum_floor#vacuum for 5 secondsvacuum(5000)ifcloggedreverse_suctionendend
ActiveRecord creates new singleton methods for instances and classes when you define associations. It may seem like magic, but that magic is just metaprogramming.
What’s an equalstilde, you say? Who would come up with such a dumb sounding name for an operator? It actually lies at the foundation of Ruby regular expressions. It allows you to apply a regular expression to a string, and returns the index within the string where the regular expression matches. For example,
1
/Lisa/=~"You're tearing me apart, Lisa!"#=> 25
2. Matchdata
Instead of using the equalstilde, you can also use a string method called match to apply a regular expression to a string. However, instead of returning an index, it returns this weird type of object called MatchData:
1
"You're tearing me apart, Lisa!".match(/Lisa/)#=> #<MatchData "Lisa">
Cool, so then what do you do with a MatchData object? It all makes sense when you learn about this crazy thing called…
3. Capture groups
Get ready to have your mind blown. In Ruby, if you use parenthesis in a regular expression, you can utilize capture groups. You can extract multiple parts from a string without using multiple regular expressions, just by putting the part of the string you want to capture. Get out, I know. It’s awesome. For example,
12345
m="""I mean, the candles, the music, the sexy dress... what's going on here?"""m.match(/the (.*), the (.*), the (.*)\.\.\./)# => #<MatchData "the candles, the music, the sexy dress..." # 1:"candles" 2:"music" 3:"sexy dress">
Then, you can access each of the capture groups separately, like so:
1234
m[0]# => "the candles, the music, the sexy dress..."m[1]# => "candles" m[2]# => "music"m[3]# => "sexy dress"
You can even name your capture groups:
12345
m="""I mean, the candles, the music, the sexy dress... what's going on here?"""m.match(/the (?<sexy_item_1>.*), the (?<sexy_item_2>.*), the (?<sexy_item_3>.*)\.\.\./)# => #<MatchData "the candles, the music, the sexy dress..." # 1:"candles" 2:"music" 3:"sexy dress">
Then you can access each group using hash syntax:
1
m[sexy_item_1]# => "candles"
4. Atomic Grouping
An atomic group is a type of capture group. When the regex engine exits it, all backtracking positions are discarded. Let’s go over two cases, one that uses atomic grouping, and one that doesn’t, and see how the regex engine would operate.
The regex engine first matches the start of the string, \A, and then matches “Tommy”. However, since it then would leave the capture group and try to match the \z, or the end of a string, the match would fail. The engine would then go back and try to match Thomas, and fail, try to match Tom, and ultimately stop and declare failure. But say we want to shorten this process.
In this case, again, the \A is matched as the start of the string, and then the engine tries to match “Tommy”. It succeeds and moves onto matching \z, which fails. Because of the atomic grouping, the engine has thrown out all back tracing data upon reaching the \z, and therefore fails after only trying to match “Tommy” rather than all three options in the capture group.
5. Subexpression Calls
Okay. Okay. This one is probably the most radical thing about regular expressions.
By using the \g syntax, you can match a previously named subexpression, which can be a group name or number. An example better demonstrates how you use it.
Say that you want to make sure all parenthesis surrounding a string are always balanced. You would use something like this:
Cool. Pretty cool. Let’s go over what the regex engine does.
Enter a capture group named paren.
Match a literal (.
Match the text in between the parenthesis that is anything except for parenthesis.
Call the paren capture group again, dropping the part in the middle of the parentheses for now.
Enter the paren capture group again
Match a literal (, the second character in the group
Match the text in between the parenthesis that is anything except for parenthesis.
Try to call paren again, but fail since it would cause the match thus far to fail.
Match a literal ) n times, where n is the depth of the recursion.
Note that the * following \g is extremely important. This allows the regular expression to break out of recursion, since the subexpression can exist 0 or many times. Without it, the recursion would be never ending.
6. Lookahead and lookbehind assertions
What if you want to make sure certain characters exist in a regular expression, but you don’t want them to be part of your match group? This is when you would want to use a special type of anchor, called lookahead and lookbeind assertions.
(?=pat) is a positive lookahead assertion, and ensures that the characters following your expression match “pat”
(?!pat) is a negative lookahead assertion, and ensures that the characters following your expression do not match “pat”
(?<=pat) is a positive lookbehind assertion, and ensures that the characters preceeding your expression match “pat”
(?<!pat) is a negative lookbehind assertion, and ensures that the characters preceeding your expression do not match “pat”
Pretty fantastic, right? For example, say you have a list of emails, and you’re trying to find the usernames of all of the ones at a certain domain:
If there’s still more you want to know about regular expressions in Ruby, I recommend looking at the Ruby Docs or visiting the webstite Regular-Expressions.info, which contains more than you’d ever want to know about regular expressions. In the best way possible.